


ZOE balls
Sample city through Trancentral, basic face kick elemental

Like rats in New York City, in 2024 it feels like you are never more than six feet away from an article about elections. It seems we’re now permanently in the run-up to some crucial vote somewhere. And during that time, subtle policy questions often take a back seat to breathless reports of the latest opinion polls. Today I will take a look at three ways that polling is hard - and I’m going to illustrate them with COVID data.
Speaking of which, there’s little to report on the COVID front. The UK is clearly well over the peak of the JN.1 wave, which despite a large number of infections had relatively small consequences in terms of hospital admissions and deaths. You might hope that some of the perma-doom crowd would reflect on how well-calibrated their dire warnings were, but I’m not holding my breath. But for now, we are on a down slope, the weather is getting warmer, and there’s not an obvious variant to drive an imminent next wave yet.
I had a fun couple of weeks since I last wrote here - the three talks I mentioned in my previous post went well, and I got to meet old and new friends on my travels. And there were various bonuses along the way, including great meals in three different Oxbridge colleges, an excellent curry on my day in between lectures, and most exciting of all, getting to ride in the Oxford Maths car lift!
But as promised, I want to explain three ways in which opinion polling is hard and often misreported: namely representativeness, trends and subsamples.
Stepping away from politics, I will illustrate them with examples from the ZOE COVID app. For non-UK readers: this was a tool used to estimate prevalence during the pandemic. The idea was that people would report their symptoms, a fraction of those would be PCR tested to find out if they had COVID, and this would be extrapolated to provide national and regional estimates of the number of infected people. It sounded great, but as you’ll see I had misgivings about how it worked in practice, and whether the statistical challenges had been properly dealt with.
Representativeness
At heart, the idea of an opinion poll is very simple, as I describe in Numbercrunch. If 40% of the population vote Labour, you’d expect that about 40% of people in a sufficiently large sample of people will do the same. Turning this on its head, if 40% of people in a sufficiently large sample vote Labour (a known measurable fact), then you can extrapolate this with a certain degree of confidence to infer that about 40% of the population will do the same (an interesting thing to learn).
However, this is never going to be perfect. If you toss a hundred fair coins, the chances are that you won’t see exactly fifty heads (though you will probably be somewhere close). In the same way, because the sample is chosen randomly, it won’t necessarily exactly reflect the underlying proportion of Labour voters. There will be a degree of sampling error, reflected in the fact that a poll of 1,000 voters will often be reported with ‘margin of error +/- 3%’ or similar.
There are deeper problems though. For the proportions to carry over, the sample needs to be representative. Ideally, everyone in the population would be equally likely to be sampled, but this is hard to achieve in practice.
Clearly, if you sampled outside the Labour conference then the people you interview would not reflect the population as a whole. But there are subtler ways in which bias can creep in. Many young people don’t have a landline or answer their phone to strangers. Older and poorer people will have less reliable Internet access. If people are paid to participate, they may be incentivised to fill in polls as fast as possible without worrying much about what they say.
Of course, pollsters are well aware of these issues and have a variety of tools to combat them, such as not weighting each response equally. However, it’s fair to say that this is subtle and needs to be done with care, and that different pollsters handle things differently, making cross-company comparisons hard.
However, it became clear during the pandemic that ZOE’s methodology was not always dealing successfully with this representativeness issue. Indeed, it should be clear that people who were COVID-conscious enough to diligently report data to the app might not be typical of the general population.
This was well illustrated in May 2021, when ZOE suddenly recalibrated their prevalence estimates having realised there were three times more unvaccinated people in the population than in their user base:
The percentage of adults in the UK who have received at least one dose of a COVID vaccination, as of 11th May 2021, is 67.3%. While this is a brilliant achievement, the number of contributors to the ZOE Symptom Study who have reported at least one vaccination as of 8th May 2021 is even higher at 89%.
Similarly, when announcing the end of their daily COVID reporting in Autumn 2023, ZOE admitted that:
people are more likely to report positive tests than negative tests.
This is not a surprise, perhaps - but it’s fair to say that expressing scepticism at the time led to some intemperate online responses.
Trends
Of course, it’s interesting to know that 40% of voters support Labour. But we’d also like to know the trend: has this proportion changed recently?
In my view, outside an election period it’s likely that little has changed, and far too much political commentary echoes xkcd cartoon 904. For people who paid attention to a big speech or policy initiative, it’s natural to assume that this might change opinions. However, it’s good to remember (see also this week’s piece by
on politics hobbyists and normies) that most voters are probably close to the Tom Stoppard position:applying for a job as a political correspondent, he was asked to name the home secretary. “I said I was interested in politics,” he replied, “not obsessed.”
Looking at the Wikipedia graph of UK opinion polling it’s striking how stable the polls have been over the last year or so. Even a controversy magnet like Donald Trump has hardly seen any change in his favourability rating over the last three years. It takes a really big event (a pandemic, two prime ministers resigning) to move the average trend line by more than about 5 percentage points in a short space of time. For that reason, it’s very likely that most daily changes in polls simply reflect different sampling errors playing out, and that you should try to ignore the short-term noise and focus on the long-term signal only.
Of course, with COVID that’s not so true. As we know, in periods of exponential growth it was possible for the number of infected people to increase by 10 or 20 percent per day, consistently for a period of weeks. This is a much stronger signal than seen in political polling, and should be relatively easy to detect.
However, there are still some issues around sampling-based methods (not just ZOE, but also REACT and the ONS survey). Because of sampling error, it is still necessary to smooth the data somewhat - to fit a straight line or simple curve through it, to help find the signal within the noise.
But again, this is somewhat subtle, and can cause issues. For example, in the infamous REACT survey of 1st October 2020, a lot of controversy came down to whether you should try to fit a single curve which explained the whole time series (version A in the plot below) or fit separate lines within the periods of time when data was sampled (version B). This figure shows how noisy the data was, with wide uncertainty on each day’s prevalence shown as vertical lines, and a variety of trend lines seem consistent with the data.

In general, there’s no absolutely right way to fit these kinds of trends. If you don’t smooth enough, you will end up with a jagged line that overfits to every piece of random sampling noise. Smoothing too much can make you miss genuine changes in trend for a while, putting it down to noise. This often arises on sites reporting smooth curves based on wastewater data, where the possibility of a peak or trough can wrongly be ruled out for too long, and trend lines are only revised later when it becomes clear that the effect was genuine.
Indeed, this occurred with ZOE’s reporting on the alpha wave hitting London in December 2020. By 15th December, it was extremely clear from reported case data that London was in a serious and fast-growing wave, but ZOE was much more relaxed, presumably because of this over-smoothing issue:
No our app does NOT see a doubling of cases every 7 days anywhere at present. The London rates are doubling roughly every 30 days with an R value of 1.1. So far our data has been accurate and ahead of other methods.
For that reason, it is best to triangulate multiple sources of data - to consider the whole collection of polling data, not just single companies, or to synthesise survey, case and hospital data into an overall view of the COVID trends.
Subsamples
One more way that people are often misled by polls is by focusing on subsamples. In addition to reporting a headline figure of Labour support, a polling company may report data broken down by age, geographical region or social class. This can provide valuable insights, but some caution is required.
Returning to sampling error, a handy rule of thumb is that the margin of error behaves like a multiple of “one over the square root of the sample size”. So, where our sample of 1,000 people was reported as +/- 3%, if we’d instead surveyed 4,000 then the margin of error would be half (one over the square root of four) the size, or +/- 1.5%.
However, this cuts both ways. If we divided our sample into nine geographical regions, then the margin of error on the proportion of Labour voters in each subgroup would be three times larger, or +/- 9%. In general, dividing up the data into smaller groups leads to wider margins of error, making it hard to be confident about the results. Worse still, it’s tempting to pick the most extreme of the nine groups to report on (“Labour suddenly seems to have a problem in the South West”).
Again, this was a problem that I felt that the ZOE app never came to terms with. While they had a laudable plan to provide local estimates of risk, some of the published numbers didn’t pass a basic smell test. For example, in October 2022, ZOE claimed that 19% of people in Sheffield currently had COVID. This is a crazily high prevalence, and it makes little sense to me that (at a time when life had mostly returned to normal after lockdown, with people mixing freely across geographical boundaries) there would be such a localized spike with low levels in neighbouring regions. That felt much more like a statistical artefact than a real thing.
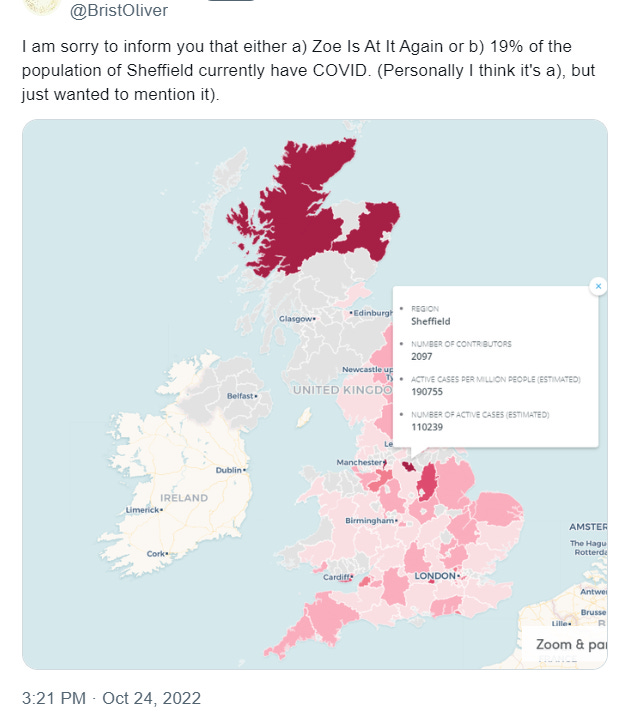
Indeed, as I described here I never found convincing evidence that these extremely high claimed prevalences converted into peaks in hospital admissions, making me even more sceptical. As time went on, the combined effect of these issues of representativeness, trends and noisy local estimates (coupled with a decline in app users) led to some implausible-looking case trajectories modelled by ZOE.
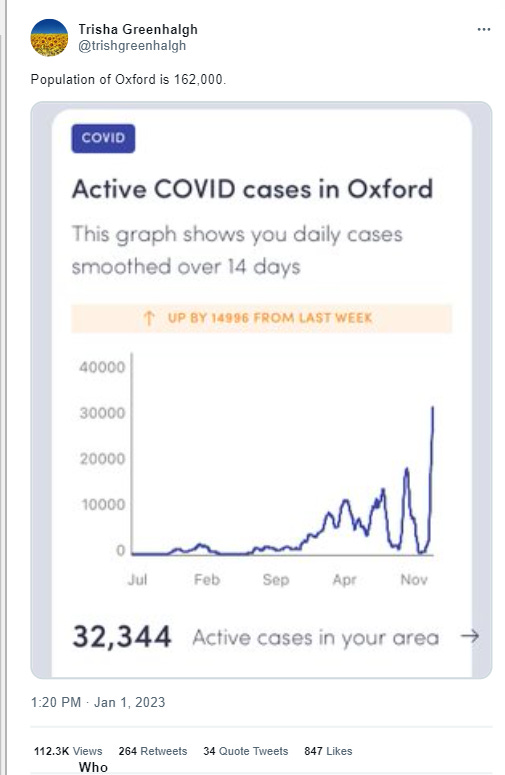
Overall then, you should be careful when reading the results of opinion polls (or indeed interpreting the results of self-selecting surveys like ZOE). In general, the media don’t do a bad job of reporting these things, but if you pin all your hopes on a self-selecting survey or identify apparent trends from regional subsamples, you may find yourself being disappointed on election night.
I've been pedantic about many ZOE Covid Study criticisms. Perhaps unfairly, given ZOE's lack of clarity. This post is well-written as I'd expect, and hits really important limitations.
Both "accurate and ahead of other methods" is my personal bugbear. It was their repeated claim, while its use of a 14 day average was often not mentioned.
They took an average of swabs from the 14 days ending on Nov 10, and used that to judge a lockdown beginning on Nov 5?
https://web.archive.org/web/20201114105840/https://twitter.com/sourcejedi/status/1327566192253526017
They later wrote a Spectator article about it, which included the same judgement. I had a direct response from Spector himself. I still can't make sense of his reasoning.
https://gist.github.com/sourcejedi/0cf3df39c94ece6d379ba9e4d4e3eadd
Do you know if the ‘as it appeared in real time’ Zoe data are available anywhere? I remember there being quite a few inconsistencies (some of which you’ve helpfully documented here) so could be useful to have the option to compare performance systematically...