


Mean Girls and The Odds Couple
You got to roll me, and call me the tumbling dice

Take a six-sided dice1 and a twenty-sided dice and roll them both. Which has the higher number on it? This isn’t a trick question, but I think there are two different answers, and the difference between them affects how we think about risk in our everyday lives.
If you’re a real nerd, you’ll be able to do this experiment for real now, and I encourage you to do that. If not, it will have to be a thought experiment, based on the following picture. Among others, there’s an orange cubic six-sided dice - what some people call a d6 - and more interestingly there’s a purple icosahedral twenty-sided dice - a d20.

(There’s an interesting diversion that this picture contains the five Platonic solids, plus the red ten-sided dice. These are the five shapes formed only of identical perfectly symmetric faces: four equilateral triangles on the blue dice, twelve perfect pentagons on the yellow dice, and so on. What’s more interesting is the fact that these five are the only possible shapes with this property, but I’m not going down that rabbit hole today).
D’You Know What I Mean?
So, roll the d6 and the d20. Which one scores higher? Well, clearly the numbers on the d20 go up higher, so it feels like we should get a bigger number there, and that intuition is fine. In fact, we can quantify it a little.
We can talk about the mean of what we might see. This is the average of the possible scores, weighted by the different probabilities of seeing them. Just like Plato, we know that these dice are symmetric, which means that the chances of seeing each score is the same2.
For the d6, there’s a one-in-six chance of seeing each outcome, and the mean is (1+2+3+4+5+6)/6, or 3.5. For the d20, there’s a one-in-twenty chance, and the mean is (1+2+3+ … +19+20)/20, or 10.5. The mean of the d20 is exactly three times bigger than the mean of the d6.
The mean tells us something about long-run averages and about fairness. Imagine Alice and Bob playing a game. Alice rolls a d20 and gives Bob a pound for each number she rolls (rolling 12 costs her £12 and so on). Bob rolls a d6 and gives Alice three pounds for each number he rolls (rolling 3 costs him £9).
Our calculation tells us that if they keep playing long enough, we’d expect Alice and Bob’s bankrolls to be roughly where they started. We’d say it was a fair game. But this average behaviour is not a guarantee, and it certainly won’t be the case that they’ll always stay exactly level. There’ll be random fluctuations in wealth in either direction, but over a long enough time these will tend to cancel out.
Take a chance on me
Nonetheless, it’s true that comparing the means, the d20 scores higher on average than the d6. But if you look again, that wasn’t exactly the question I was asking. Implicitly I wasn’t suggesting doing the experiment again and again, but rather making a single roll of each dice. As I explained in my Nate Silver piece a few months back, this is where things get murkier.
The point is that anything is possible, and we can’t know what will actually happen. It’s entirely plausible that I roll a 2 on the d20 and a 5 on the d6, say, whatever the means might tell us. But asking “is it possible” isn’t always helpful: instead we need to calibrate “is it likely”? That’s where the second way of thinking comes in. Instead of thinking about means, we can think about odds or about probabilities.
There are 120 possible pairs of outcomes of the two rolls taken together. Again, symmetry is on our side, so each of these pairs are equally likely and we just need to count the ways that the d6 can beat the d20. If the d20 scores 1, there are five d6 rolls that beat it (2,3,4,5,6). If the d20 scores 2, there are four. A 3 can be beaten three ways. The pattern continues, until a d20 score of 5 can only be beaten one way.
What this means is that there are 5+4+3+2+1 = 15 ways that the d6 beats the d20. As a probability it’s 15/120, or a 1 in 8 chance. In other words, 12.5% of the time, the smaller dice will come out ahead. A further 5% of the time (6/120) the two scores will be exactly the same.
So, it’s pretty likely that the d20 will win, but it’s not a guarantee. There’s a degree of uncertainty baked into the experiment, and less likely outcomes do happen some of the time.
It’s important to realise that the two philosophies, the mean-based long run average and the single shot dice roll, are telling us different and complementary things. The d20 having a higher mean does not invalidate the experience of someone who rolls higher on the d6, but equally a one-off experiment where we roll higher on the d6 doesn’t change the fundamental fact about the means.
Bad medicine
I think the difference between these two ways of thinking underpins a lot of discussions about health, and explains why five years since COVID first emerged some people are still talking past each other.
When we talk about the severity of a disease, we are thinking in the language of means. Instead of thinking about average behaviour across successive dice rolls, we are looking at an average across the population, but the effect is the same. For example, take this graph from the JCVI showing intensive care admissions numbers for COVID.
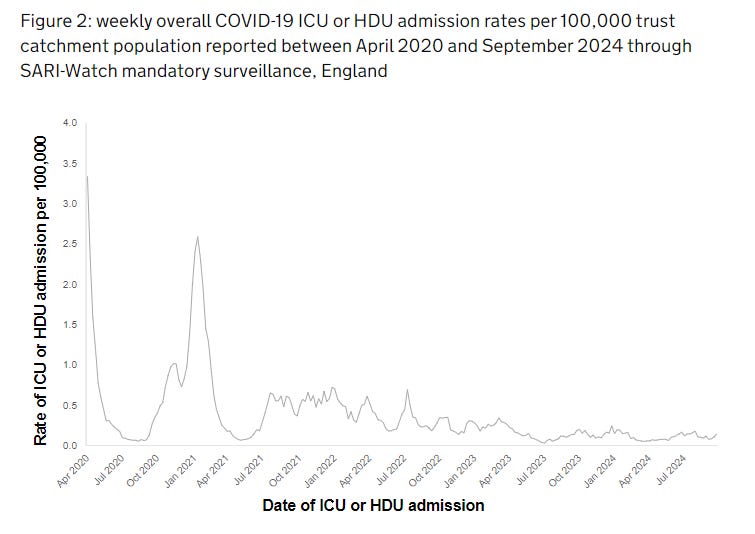
It represents a stunning level of success - largely due to vaccination, but also due to immunity from infection and the intrinsic lower severity of omicron. Despite COVID circulating very widely - some of the peak levels of infection in the last two years have been as high as ever - almost nobody is ending up in intensive care because of it. (The most recent number is 77 people in High Dependency Units across England - it’s almost a one in a million event). That’s great news!
However, of course, some people do still end up in ICU. Just as we can’t guarantee that the d6 won’t beat the d20, we can’t guarantee someone won’t have a very severe infection3. It’s no consolation to the relative sitting outside the ward to know that it was an unlikely outcome - and there’s not much more that we can say than “sorry, that’s terrible”. Certainly quoting population-level severity data wouldn’t be a tactful or reasonable way to respond to them.
This is the point where the two philosophies can diverge in terms of what, if anything, we should do about COVID in 2024. Some people will argue that because the probability of an infection leading to ICU isn’t zero, the only sensible action is to avoid infection altogether.
Similarly people posting weekly COVID updates will tell us that “Long Covid remains a risk for all”. Of course, that’s true in the sense that the risk isn’t zero. But equally, the risk of being speared by ice falling from a plane isn’t zero, but nobody would think it was rational to stay permanently inside to avoid it. Really, the only thing we can do is to calibrate the risk.
Based on ONS (gold standard randomly-sampled) data about infections and Long COVID severity, Jean Fisch on Twitter has estimated that in the world of 2023, 0.3% of COVID infections led to Long COVID severe enough to have a lot of impact on peoples’ daily activities.
I can’t tell you what to do with this information. It’s a lot lower than some people will quote to you. It’s about a third of the chance of simultaneously rolling 20 on the d20 and 6 on the d6. But it’s up to you to decide how to lead your life based on it.
Personally I think everything we do comes with tradeoffs, and that we shouldn’t just optimise health outcomes at any cost. I’m with the great statistics communicator David Spiegelhalter, who says in another context that “20 seconds [of life] gained per pint not drunk … may seem a poor return for the perceived cost of pleasure foregone”, but that’s something you have to decide for yourself.
But certainly I feel we’d all do a bit better by at least acknowledging these two different ways of thinking, and the fact that some people may prefer one or the other. The claim that Long COVID is less likely on reinfection is not invalidated by anecdotes of people who got it second time round. But equally it’s perfectly valid to say that population-level statistics are no guarantee at an individual level, and it can be worth taking reasonable worst-case scenarios seriously, depending on risk and severity.
Coda: Bluesky, Neo Nerdery, doing sums
My piece about Bluesky last weekend annoyed some sensible people. There was perfectly reasonable push back on “echo chambers” (ironically from people on the right of the spectrum!) from
here and here. I think the annoyance was partly because of screenshots which left out my comments about the enshittification of Twitter, so some people assumed I was advocating for that site - which was very far from my intention. Rather than trying to defend one or the other, I was really querying the value of Twitter- or Bluesky-style social media full stop (see also this from and this from ) and suggesting that the answer might be something closer to Substack. I very much feel there’s room for a platform where people are happy to read reasonable and hopefully well-argued stuff that they sometimes disagree with. That’s fine in principle, except for the fact that twenty or more people unsubscribed off the back of the Bluesky piece, so maybe I was being a bit optimistic about that!I really enjoyed the Brawn GP series about the 2009 Formula 1 season - it’s on iPlayer in the UK, and I think on Hulu elsewhere? It’s a great underdog story, with some heroes (drivers and engineers) and villains (Bernie Ecclestone and others). It was just the right level of F1 nerdery for me, and offered the unlikely bonus of some excellent interviews by the highly bodacious Keanu Reeves.
Despite my new job still being insanely busy, I actually managed to make some progress with research this week, which I’m pleased about. And from a separate project, my PhD student just put our new paper on the arxiv, talking about simulating physical processes which “ground” (become zero for example) on a significant proportion of the parameter space.
Yes, I know the word is die. But it sounds wrong. Sorry.
Shout out to the forthcoming book by
, from which I learn that this isn’t strictly true, and that the dimples on a traditional “spotty” dice means that the chances aren’t all the same. So sue me.In practice it’s a little bit more complicated because not everyone is rolling the same dice: different people have different levels of risk, but still it makes sense to think of the observed population-level severity as an average of all of these individual levels of risk at the time.
I’m sad to hear about people unsubscribing when what you wrote is excellent and thoughtful. I have subscribed to make up for one of those losses!
For me the chief value of Twitter has been discovering people like you. The only way that it has become "shittier" in my experience is that some writers whose work I found enlightening no longer post here.